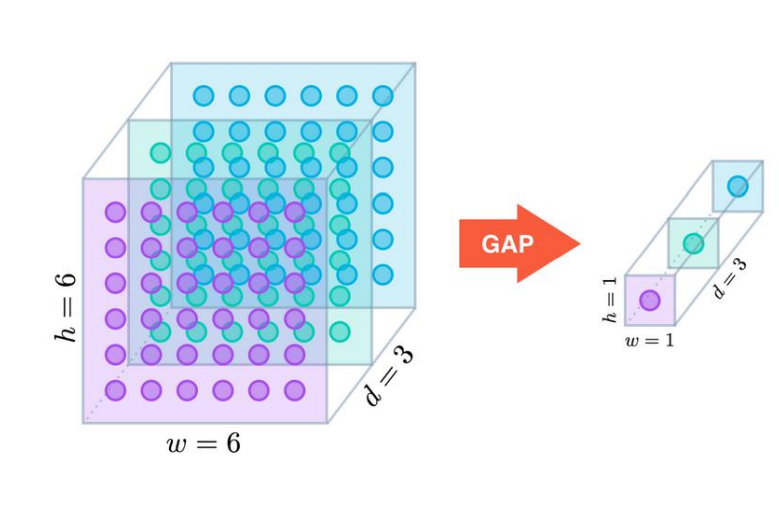
Global Average Pooling 이란 Global Average Pooling은 feature map 의 가로 x 세로 의 특정 영역을 sub sampling 하지 않고, 채널 단위로 평균 값을 추출하는 방법이다. 3차원 Feature map 을 1차원 Dense Classification layer에 연결 시, 많은 연결 노드와 파라미터가 필요하다. 예를 들어 (8 , 8, 512 ) 의 Feature map을 Flatten으로 1차원 형태로 바꾸면 8 x 8 x 512 = 32,768의 파라미터가 생기고, 여기서 100개의 뉴런으로 구성된 Layer에 연결하면 32,768,000개의 파라미터가 생긴다. 하지만 Global Average Pooling을 사용하게 되면 효과적으로 노드와 파라미터..