들어가며
만일 새로운 task에 대해서 동작하는 인공지능 모델을 개발하는 업무를 담당하게 되었다고 생각해보자. 새로운 task이기 때문에 먼저 레이블링된 데이터를 확보해야하는데, 이 data annotation 과정은 시간과 금전적으로 부담되는 작업일 뿐더러, annotation 품질에 대한 이슈도 있어 매우 어려운 작업이다. 이러한 어려움을 극복할 수 있는 방안으로는 Transfer Learning을 활용할 수 있다.
Transfer Learning (전이학습)
Transfer Learning은 데이터셋에서 학습하며 배웠던 지식을 다른 데이터 셋에서 활용하는 기술이다. 즉, 특정분야에서 학습된 신경망의 일부능력을 유사하거나 새로운 분야에서 사용되는 신경망의 학습에 이용하는 방법이라는 것이다. 전이학습은 학습 데이터의 수가 적을 때 효과적이며, 높은 정확도를 비교적 짧은 시간 내에 달성할 수 있다.
전이학습에서 이용되는 학습된 신경망을 pretrained model 이라고 부르며 대표적으로 ImageNet, ResNet, GoogleNet,VGGNet 등이 있다. 대규모의 데이터셋으로 잘 훈련된 이 pretrained model을 가지고 사용자가 적용하려고 하는 문제 상황(data set의 규모, pretrained model data set과 문제 상황에서 사용되는 data set의 연관성 등) 에 맞게 모델의 가중치를 약간씩 변화하여 사용한다.
pre-trained 모델을 불러와 pre-trained 모델의 파라미터를 적용하는 것을 transfer-learning이라고 하고, 문제 상황에 맞게 모델의 가중치를 조정하는 과정을 fine-tuning이라고 한다.
쉽게 예로 들자면, 우리는 개와 고양이 이미지 데이터 셋을 분류하고 싶다. 여기서 우리는 이미 개와 고양이 같은 수 많은 동물들의 class를 분류한 모델들을 알고 있다. google net , resnet, vgg net ... 이렇게 학습된 모델을 불러와서 학습된 모델의 파라미터를 적용하는 것을 transfer learning 이라고 한다. 현재 task에서는 개와 고양이 이진분류만 하면 되므로 FC layer을 이진분류로 바꿔주는 조작을 수행한다. 이 과정을 fine-tuning 이라고 한다.
Fine-tuning (미세조정)
사전학습 된 모델을 활용하여 새로운 모델에 학습하는 과정을 의미
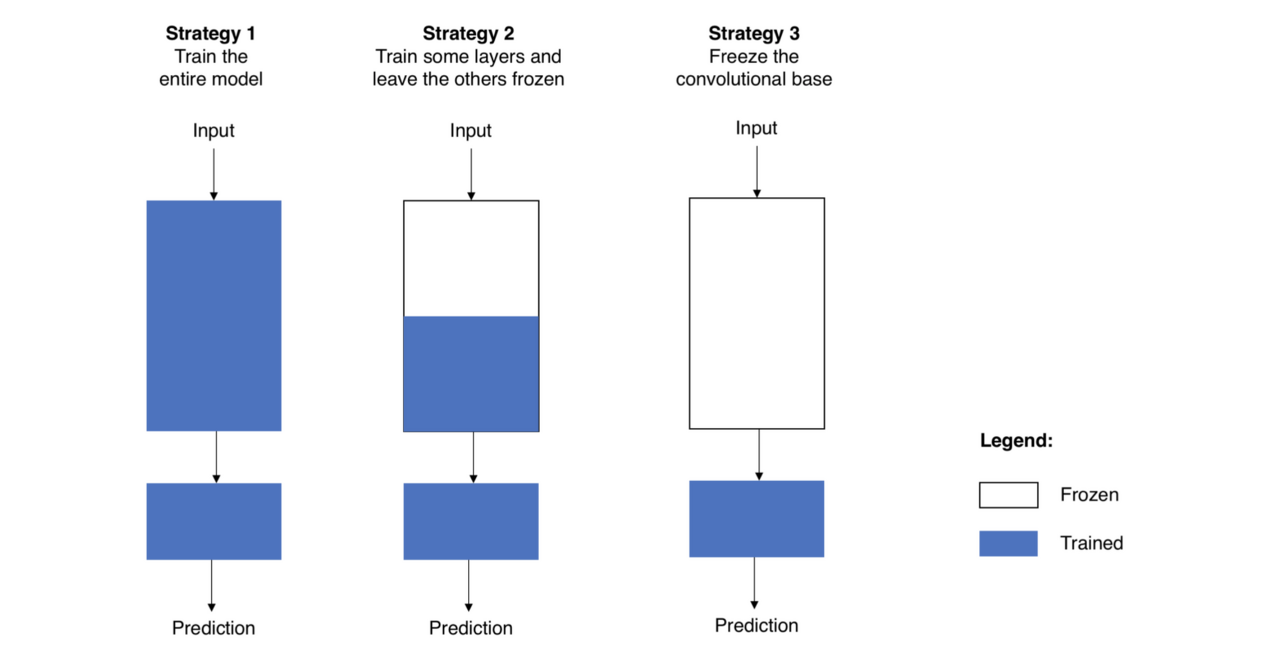
Fine tuning의 3가지 방법
전략 1. 전체 모델 새로 학습
- 사전학습 모델의 구조만 사용하면서, 내 데이터 셋에 맞게 전부 새로 학습시키는 방법
- 큰 사이즈의 데이터 셋이 필요하다
전략 2. Conv base의 일부분은 고정(Freezing)시키고, 나머지 Conv base계층과 Classifier 새로 학습
- 낮은 레벨의 계층을 일반적이고 독립적인 특징(신형성)을 추출하고, 높은 레벨의 계층은 보다 구체적이고 명확한 특징(형상)을 추출한다
- 이러한 특성을 고려하여, 우리는 신경망의 파라미터 중 어느정도까지 학습시킬지를 정한다
- 만일 데이터 셋이 작고 모델의 파라미터가 많을 경우, 오버피팅이 될 위험이 있으므로 더 많은 계층은 건들이지 않는다
- 데이터 셋이 크고 그에 비해 모델이 작아서 파라미터가 적다면, 더 많은 계층을 학습시켜서 내 프로젝트에 더 적합한 모델로 발전 시킨다
전략 3. Conv base는 고정(Freezing)시키고, Classifier만 새로 학습
- 컴퓨팅 연산 능력이 부족하거나, 데이터 셋이 너무 작을 때 학습하는 방법
- task가 pre trained model 의 데이터 셋과 매우 비슷할 때 학습하는 방법
전략1과 전략2에서는 사전 학습된 지식을 최대한 보존하기 위해 learning rate를 FC layer에 비해 작은 값으로 설정하여 학습해야한다.
데이터 크기와 유사성에 따른 Fine-tuning 전략

상황 1. 크기가 크고 유사성이 작은 데이터 셋일 때
이 경우는 [전략1]이 적합하다. 데이터 셋의 크기가 크므로, 모델을 다시 처음부터 내가 원하는대로 학습시키는 것이 가능하다. 사전 학습 모델의 구조와 파라미터들을 가지고 시작하는 것은 아예 처음 시작하는 것보다 유용할 것이다
상황 2. 크기가 크고 유사성도 높은 데이터 셋일 때
이 경우는 어떤 선택을 하던 상관없지만 [전략2]가 효과적이다. 데이터 셋의 크기가 커서 오버피팅 문제가 되지 않고, 원하는 만큼 학습시켜도 된다. 하지만, 데이터 셋이 유사하다는 이점이 있어 이전에 학습한 지식을 활용하지 않을 이유가 없다.따라서 classifier와 conv base의 높은 레벨 계층 일부만 학습시켜도 충분할 것이다
상황 3. 크기가 작고 유사성도 작은 데이터 셋일 때
이 경우는 가장 worst인 상황이다. 상황을 바꿔보는 것이 좋지만 불가능하다면, 시도해볼 수 있는 전략은 [전략3] 이다. 하지만 conv base 계층 중 몇 개의 계층을 학습시키고 몇개를 freezing 해야하는지 알아내가 어렵다. 너무 많은 계층을 새로 학습시키면 작은 데이터셋에 모델이 과적합될 우려가 있고, 너무 적은 계층만 학습시키면 모델은 제대로 학습되지 않을 것이다. 상황 2보다는 조금 더 깊은 계층까지 새로 학습시킬 필요가 있다. 또한, 작은 크기의 데이터셋을 보완하기 위해 data augmentation같은 테크닉을 시도해봐야 할 것이다.
상황 4. 크기는 작지만 유사성이 높은 데이터 셋일 때
이 경우에는 [전략4]이 최선의 선택이다. 이 경우는 기존의 conv base는 특징 추출기로써 사용하고, classifier 부분만 변경하여 학습한다.
📝참고자료
https://jeinalog.tistory.com/13
Transfer Learning|학습된 모델을 새로운 프로젝트에 적용하기
#Transfer Learning #전이학습 #CNN #합성곱 신경망 #Image Classification #이미지 분류 이 글은 원작자의 허락 하에 번역한 글입니다! 중간 중간 자연스러운 흐름을 위해 의역한 부분들이 있습니다. 원 의미
jeinalog.tistory.com
https://inhovation97.tistory.com/31
Transfer learning & fine tuning의 다양하고 섬세한 기법
우리가 어떤 문제에 직면했을 때 해당 문제와 비슷한 결과들이 있다면 훨씬 수월하고 빠르게 문제를 해결해 나갈 수 있을 겁니다. 이번에는 바로 그 개념인 *Transfer learning과 **fine tuning에 대한 내
inhovation97.tistory.com
'컴퓨터비전(Computer Vision)' 카테고리의 다른 글
| 파이토치(Pytorch)[4] - 선형 회귀(Linear Regression) (1) | 2023.10.27 |
|---|---|
| 파이토치(Pytorch)[2] - 경사하강법 (0) | 2023.10.24 |
| 데이터 부족 완화[1] - Data Augmentation (0) | 2023.10.19 |
| 컴퓨터 비전의 시작 (1) | 2023.10.18 |
| Object Detecion [3] - FAST R-CNN (0) | 2023.10.17 |