2번.
A) 벡터집합 x1,x2,....,xN을 이루는 벡터의 선형 조합이 영벡터가 되도록 하는 스칼라 계수 c1,c2,...,cN가 존재하면 이 벡터들은 선형 종속이라고 합니다. 반대로 벡터들의 선형조합이 0이 되면서 모두 0이 아닌 계수들이 존재하면 그 벡터들은 선형 독립이라고 합니다. 또한, 직교하는 두 벡터의 내적은 0이됩니다.
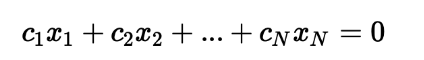
3번.
- 이산형확률 변수는 확률변수가 가질 수 있는 경우의 수를 모두 고려하여 확률을 더해서 모델링한다

- 밀도는 누적확률분포의 변화율을 모델링하며, 밀도를 특정 구간에 대하여 정적분하면 이것이 연속형 확률변수가 특정 구간에 포함될 확률이다.
- 몬테카를로 샘플링 방법은 변수 유형 (이산형, 연속형)에 상관없이 사용할 수 있다.
4번. 다음은 정규화 방식에 대한 설명입니다. 해당 용어에 대한 설명이 올바르지 않은 것을 고르세요.
① Overfitting : 오버비팅은 주로 매개변수가 많고 표현력이 높은 모델이나, 훈련 데이터가 적은 경우에 발생한다.
② Parameter Norm Penalty : 손실함수에 Norm Penalty Term을 추가하여 사용하여 활용하며 L1 Norm, L2 Norm 등이 있다.
③ Batch Normalization : 배치 정규화는 초깃값의 영향을 크게 받기 때문에 주의하여야 한다.
⇒Batch Normalization은 초기값의 영향을 줄여주는 효과가 있어, 초기화에 민감하지 않은 모델을 만드는데 도움을 준다.
④ Noise Robustness : 레이어 중간에 노이즈를 추가하여 과적합을 해결하는 방법론이다.
⑤ Early Stopping : 모델의 과적합을 방지하기 위해 이전 에폭(학습 반복 회수)에 비해 검증 오차(Validation Loss)가 감소하다 증가하는 경우 학습을 종료
5번. 다음 중 신경망에서 활성함수가 필요한 가장 적절한 이유를 고르세요
활성함수란 ? 입력 신호의 총합을 출력 신호로 변환하는 함수를 일반적으로 활성화 함수라고 한다.
⑤ 비선형 근사를 하기 위해서
활성함수는 신경망에서 비선형성을 도입하는 역할을 한다. 비선형 활성함수를 사용하지 않으면 신경망은 여러층으로 구성되어도 단일 선형 변환으로 축소 될 것이며, 복잡한 데이터 패턴을 학습하기 어려워진다. 따라서 비선형 활성함수를 사용하여 신경망이 비선형 함수를 근사하고 복잡한 데이터 패턴을 학습할 수 있도록 한다. ( 활성함수를 사용하지 않으면 신경망은 선형모델과의 차이가 없다)
8번.다음 중 경사하강법에 대한 설명 중 옳지 않은 것을 고르세요.
① 기계학습 문제는 대부분 학습 단계에서 최적의 매개변수(가중치와 편향)를 찾아야 한다.
② 이때, 기울기를 통해 함수의 최솟값, 혹은 가능한 한 작은 값을 찾으려 하는 것을 경사법이라고 한다.
③ 미분이 가능한 함수 f에 대해 주어진 점 (x, f(x))에서의 접선의 기울기가 음수라면, x를 증가시키면 함수값 f(x)가 감소한다.
④ 경사하강법을 통해 구한 함수의 극소값의 위치는 해당 함수의 최솟값의 위치이다.
⇒경사하강법은 함수의 극소값을 찾는 알고리즘이지만, 항상 전역 최소값을 찾는 것을 보장하지 않는다.
⑤ 경사하강법은 비볼록 함수, 안장점 등에서의 한계점이 존재한다.
A) 딥러닝에서 다양한 경사하강법 기법들을 활용하여 최적화를 진행합니다. 딥러닝의 목표는 예측값과 정답의 차이인 손실함수의 크기를 최소화할 수 있도록 가중치를 업데이트하는 것입니다. 경사하강법은 최적값을 찾기 위해서 손실함수를 편미분한 기울기에 학습률을 곱한 값을 빼서 업데이트를 진행하는 것입니다.
경사법은 현 위치에서 기울어진 방향으로 일정거리만큼 이동하며 반복하여 함수의 값을 점차 줄여나갑니다. 다만, 극값에서의 미분 값은 0이므로 더 이상 업데이트를 할 수 없습니다. 따라서 경사하강법을 실행하는 도중에 함수의 최솟값이 아닌 극솟값에 빠지면 목적함수의 최적화가 자동으로 종료되므로, 경사하강법을 통해 구한 함수의 극솟값의 위치가 항상 해당 함수의 최솟값이라고 할 수 없습니다.
7번. 흔히 classification task에서는 cross-entropy를 목적식으로 활용합니다. 후에 다른 강의들에서는 KL-divergence loss 등을 확인할 수 있을텐데요. KL-divergence는 확률분포 사이의 차이를 비교할 때 사용하는 방법 중의 하나입니다. 가령, 확률 분포 P를 모델링하여 확률 분포 Q를 얻었을 때, 모델링한 Q가 원래의 P와 얼마나 차이가 나는 지 확인할 때 사용합니다.
이 때, 주어진 확률분포 P, Q 에 대하여, cross-entropy H(P,Q) 수식을 entropy H(X) 와 KL-divergence KL (X|Y) 로 표현할 수 있는데요. 수식이 아래와 같을 때, cross-entropy와 KL-divergence의 관계를 올바르게 표현한 것은 어떤 것일까요?
A) cross entropy란 확률분포 두 개에 대한 불확실성을 나타내는 척도이다. 쿨백-라이블러 발산(Kullback-Leibler Divergence, KLD)은 두 확률분포 간의 차이를 측정하는 함수다. 즉 크로스 엔트로피에서 엔트로피를 빼준 값이 KL Divergence 값이다.

⇒ H(p,q) = KL(p||q)+H(p)

9번 . 연속적인 변수에 대한 함수의 convolution 연산

10번. 시퀀스데이터에 대한 설명중 가장 적절한 것을 고르세요.
① 대표적인 시퀀스 데이터에는 소리 데이터, 문자열 데이터, 주가 데이터, 이미지 데이터 등이 있다
⇒ 시퀀스데이터는 과거정보 또는 맥락과 관련이 있는 데이터, 이미지 데이터는 크게 상관없는 경우가 많다.
② 시퀀스 데이터를 학습시켜 모델을 생성하는 시퀀스 모델링은 일대다, 혹은 다대일 모델링만이 가능하다.
⇒일대다(이미지 캡셔닝), 다대일(감성분석),다대다(번역) 모델링 3가지가 가능하다.
③ RNN의 잠재변수는 다음 순서의 잠재 변수를 모델링하기 위한 입력 값으로 사용될 수 있다.
⇒ RNN은 이전 순서의 잠재변수와 현재의 입력을 활용하여 모델링한다
④ LSTM의 입력(Input) 게이트는 새로운 정보 중 어떤 것을 버릴 지, 망각(Forget) 게이트는 새로운 정보 중 어떤 것을 저장할 지 결정하게 된다.
⇒ 입력 게이트는 새로운 정보 중 어떤 것을 저장할지, 망각 게이트는 새로운 정보 중 어떤 부분을 버릴지 결정
⑤ 시퀀스의 길이가 길어지는 경우, Vanila RNN에서 발생할 수 있는 기울기 소실 문제를 해결하기 위해 LSTM, GRU, CNN 등의 기법을 사용할 수 있다.
⇒ CNN은 기울기 소실 문제를 해결하기 위해 고안된 방법이 아님.
오답개념정리
▢ 사슬법칙
: 조건부 확률과 결합확률 관계를 확장한 것
p(x1,x2,x3) = p(x1∩x2∩x3) = p(x1∩(x2∩x3)) = p(x1|x2∩x3)p(x2∩x3)
= p(x1|x2∩x3)p(x2,x3) = p(x1|x2,x3)p(x2|x3)p(x3)
Q) RNN에 대한 설명으로 올바르지 않은 것은?
- RNN은 hidden 노드가 방향을 가진 엣지로 연결되어 순환구조를 이루는 인공신경망의 한 종류이다.
- RNN은 input 길이에 비례하여 모델 parameter가 증가한다.
⇒ RNN은 input 길이에 상관없이 동일한 parameter를 가지고 동작하는 모델이다.
- RNN은 input 길이가 길어질수록, 역전파시 그래디언트가 점차 줄어 학습능력이 떨어진다.
- RNN의 변형 종류로는 GRU, LSTM 등이 있다.
Q) 다양한 Gradient Descent 기법들 설명에 대해 옳지 않은 것을 고르시오.
① 경사하강법(Gradient Descent)는 손실함수의 기울기(Gradient) 값에 학습률을 곱한 후 이를 빼 가중치 업데이트를 진행한다.
② Adagrad는 이전 기울기(Gradient)의 누적 제곱합에 비례하도록 학습률을 조정하여 업데이트를 진행 한다.
③ Momentum은 SGD에 가속도항을 추가하여 기울기의 관성 효과를 가져온다.
④ RMSProp은 지수 가중 이동 평균을 활용하여 이전 기울기를 더 크게 반영한다.
⑤ Adam은 Momentum 계열과 Ada 계열을 합친 기법이다.
A) 다양한 Gradient Descent 기법
딥러닝의 목표는 예측값과 정답의 차이인 손실함수의 크기를 최소화 할 수 있도록 가중치르 업데이트 하는 것이다. 경사하강법은 최적값을 찾기 위해서 손실함수를 편미분한 기울기에 학습률을 곱한 값을 빼서 업데이트를 진행한다. 여기서 학습률(에타)는 해당 기울기가 얼만큼 이동할지 결정하는 하이퍼파라미터이다.

- 경사 하강법(Gradient Descent) : 전체 데이터셋을 바탕으로 진행하기에 학습 수렴 속도가 느림. 이를 효율적으로 빠르게 최적화 하기 위한 방법론들이 등장 ⇒ 확률적 경사하강법 (SGD), 미니배치 경사하강법(Mini-Batch Gradient Descent)
- 확률적 경사하강법(SGD) : 전체 데이터 셋이 아닌 무작위로 추출한 샘플 데이터 셋에 경사하강법을 진행하는 방법
- 미니배치 경사하강법(Mini-Batch Gradient Descent) : 각 배치 안에서 미니배치를 활용하여 SGD를 진행하는 방법
⇒ but, Local Minimum, Plateau 현상 등의 문제점 존재
- Momemtum : 기울기에 관성효과를 이용하여 더 빠르게 최적값에 도달할 수 있는 방법론. 이는 Gradient Descent에 가속도항을 추가하여 기존 가중치가 감소하던 (혹은 증가하던) 방향으로 더 많이 변화하여 Local Minimum 문제 해결
- Adam: Mometum 계열과 Ada 계열을 합친 기법
▢ 학습률 조절한 기법
- Adagrad : 각 가중치마다 학습률을 Adaptive하게 , 다르게 조절하여 각 가중치별 특성을 고려하여 학습을 효율적으로 돕는 방법론, 이는 각 Gradient 마다 이전 기울기의 누적 제곱합에 반비례하도록 학습률을 조정하고 업데이트를 진행 ( 이전에 큰 기울기로 업데이트가 진행된 가중치는 작게 업데이트, 이전에 작은 기울기로 업데이트가 진행된 가중치는 큰 비율로 업데이트)
- RMSProp : 지수이동평균을 활용하여 업데이트를 진행. 즉, 가장 최근 time step의 기울기를 많이 반영하고, 과거의 기울기는 조금만 반영하게 된다. 마지막으로 Adam은 Momentum과 Ada 계열 중 하나인 RMSProp의 장점만을 결합한 알고리즘이다.
Q) 다음은 RNN 계열 모델인 Vanilla RNN, LSTM, GRU에 대한 설명이다. 다음 중 모델에 대한 설명으로 옳은 것은?
① Vanilla RNN에서는 시퀀스가 매우 길어도 앞쪽 정보가 뒤에 있는 타임 스텝까지 충분히 전달된다.
⇒ 시퀀스가 매우 길어도 앞쪽 정보가 뒤에 있는 타임 스텝까지 충분히 전달되지 x
② LSTM은 Vanilla RNN에 비해 장기의존성(Long Term Dependency)을 해결하지 못한다.
⇒ Vanilla RNN에 비해 장기의존성(Long Term Dependency) 해결
③ LSTM의 입력(Input) 게이트는 새로운 정보 중 어떤 것을 저장할 지 결정한다.
④ LSTM의 망각(Forget) 게이트는 새로운 정보 중 어떤 부분을 버릴 지 말지 결정한다.
⇒ 과거 정보를 버릴지 말지 결정
⑤ GRU는 LSTM과 마찬가지로 입력(Input), 망각(Forget), 출력(Output) 게이트로 이루어져 있다.
⇒ GRU는 reset , update 게이트로 이루어짐
A)
- Vanilla RNN은 이전 Cell의 output 값이 현 시점의 input과 함께 연산이 되는 방법론입니다. 하지만 Vanilla RNN에서는 시퀀스가 매우 길어지면 앞쪽 정보가 뒤에 있는 타임 스텝까지 충분히 전달되지 못하는 장기의존성(Long Term Dependency) 문제를 해결하지 못합니다.
- LSTM(Long Short Term Memory)은 입력(input) 게이트, 망각(forget) 게이트, 출력(Output) 게이트를 활용하여 장기의존성 문제를 해결하고자 합니다. 입력게이트는 새로운 정보 중 어떤 것을 저장할지 결정하는 게이트입니다. 또한, 망각게이트는 과거의 정보 중 어떤 부분을 버릴지 말지 결정하는 게이트이며, 출력게이트는 입력된 데이터 중 정보 어떤 정보를 출력으로 내보낼 지 결정하는 게이트입니다.
- GRU 는 LSTM의 변형구조로 Update Gate, Reset Gate만 존재하며 Output Gate는 존재하지 않아 LSTM에 비해 파라미터 수가 더 작은 모델이다.
▢ 과적합과 과소적합
과적합(Over fitting)은 모델이 학습 데이터셋을 지나치게 학습하여 발생하는 문제로 학습 데이터 셋에서는 성능이 높게 나타나지만, 평가 데이터셋 에서는 오히려 성능이 떨어지는 현상을 의미
- 훈련 데이터 추가
- 더 작은 모델 활용
- Dropout, Regularization Method, Early stopping rule 활용
과소적합(Under fitting)은 과적합의 반대 개념으로 모델이 충분히 학습 데이터를 학습하지 않은 상태를 의미
- 학습을 더 오래 진행 혹은 큰 모델을 활용하여 문제 해결
Q) 32(H)*32(W)*3(C)의 이미지를 10개의 3*3 필터로 보폭(Stride)이 1, 패드(pad)는 0으로 합성곱 연산을 진행한다고 했을 때 피처맵 크기를 구하시오.

O = (32 -3 + 0) /1 + 1 = 30
따라서 output 사이즈는 30*30이며, F*F 크기의 필터 n개를 출력으로 나오는 피처맵의 크기는 O*O*n이다.
▢ 선형종속과 선형독립
선형독립이란?
: v1,v2,...vn의 벡터 중 하나인 vj가 이전 벡터들의 선형결합으로 표현되지 않는 경우를 의미. 즉, x1v1+x2v2+ ... +xnvn = 0 을 만족하는 해인 x1,x2,...xn가 모두 0인 경우를 의미. 따라서 선형독립인 경우 선형 방정식의 해는 유일하다.
선형종속이란?
: 선형독립과 반대로 v1,v2,...vn의 벡터 중 하나인 vj가 이전 벡터들의 선형결합으로 표현되는 경우를 의미한다. 즉, x1v1+x2v2+ ... +xnvn = 0 을 만족하는 해인 x1,x2,...xn 중 0이 아닌 xi가 존재하는 경우를 의미. 그러므로 선형종속인 경우 선형 방정식의 해는 여러개가 존재
2개의 벡터인 v1,v2가 존재한다고 가정했을 때, 이는 기하학적으로 평면인 span(v1,v2)를 나타낸다. 여기서 span이란 벡터들의 선형결합으로 나타낼 수 있는 모든 벡터의 집합을 의미한다. 만약 v3이 v3 = 2v1+3v2 등 v1,v2의 선형결합으로 표현된다면 이는 v3가 해당 평면안에 표현되며 v3 € span(v1,v2)를 의미한다. 결과적으로 하나의 벡터가 이전 벡터들의 선형결합으로 표현가능한 선형종속은 span을 증가시키지 못하고 Span(v1,v2)과 동일해진다.
▢ 부분공간, 기저, 열 공간, 계수
- 부분공간(Subsapce): 선형 결합에 닫혀있는 벡터공간 R^n의 부분집합이다. 여기서 선형결합에 닫혀있다는 의미는 Subspace 내 벡터들이 선형결합을 통해서 새로운 벡터를 만들어내도 그 벡터는 Subspace안의 또 다른 벡터라는 의미입니다.
- 기저: 2가지 조건을 만족하는 부분공간 벡터들의 집합이다.
1) 첫 번째는 해당 벡터들의 Span으로 부분공간 전체를 표현 가능(Fully Span)해야한다.
2) 두 번째는 기저의 모든 재료 벡터들은 선형 독립이어야 한다.
부분공간 전체를 Fully Span 하는 선형 독립인 벡터의 조합은 여러개가 있을 수 있기 때문에 기저는 유일하지 않다. 하지만 기저를 구성하는 벡터의 개수는 유일하며 여기서 기저를 구성하는 벡터의 개수를 차원이라고 정의한다.
- 열 공간(Column Space): 행렬의 열 벡터(Column Vector)를 선형결합하여 얻어지는 벡터 공간을 의미한다.
- 계수(Rank): 해당 열 공간의 차원을 의미하는데요. 즉, 열 공간에서 기저를 구성하는 벡터들의 개수를 의미한다고 할 수 있습니다.
▢ 순전파,역전파
다층 퍼셉트론(MLP)으로 학습 한다는 것은 최종 출력값과 실제값의 오차가 최소화되도록 가중치와 편향을 계산하여 결정하는 것이다. 순전파는 알고리즘에서 발생한 오차를 줄이기 위해 새로운 가중치를 업데이트하고, 새로운 가중치로 다시 학습하는 과정을 역전파 알고리즘이라고 한다.
순전파 : 입력층에서 은닉층 방향으로 이동하면서 각 입력에 해당하는 가중치가 곱해지고, 결과적으로 가중치 합으로 계산되어 은닉층 뉴런의 함수 값(시그모이드)이 입력된다.
역전파 : INPUT과 OUPUT의 값을 알고 있는 상태에서 신경망을 학습 시키는 방법이다. 이 방법을 Supervised learning (지도학습)이라고 한다. 초기 가중치 weight 값은 랜덤으로 주어지고 각각 노드들은 하나의 퍼셉트론으로, 노드를 지날때 마다 활성함수를 적용한다.
'컴퓨터비전(Computer Vision)' 카테고리의 다른 글
| 컴퓨터 비전의 시작 (1) | 2023.10.18 |
|---|---|
| Object Detecion [3] - FAST R-CNN (0) | 2023.10.17 |
| Object Detecion [2] - SPPNET (0) | 2023.10.16 |
| Object Detecion [1] - R-CNN (0) | 2023.10.16 |
| 객체탐지 - IoU /python 코드 (1) | 2023.10.15 |